 |
Podcast: Impact AI
Foundation Model Series: Harnessing Multimodal Data to Advance Immunotherapies with Ron Alfa from Noetik
In this episode, I'm joined by Ron Alfa, MD, PhD, Co-Founder and CEO of NOETIK, to discuss the groundbreaking role of foundation models in advancing cancer immunotherapy. Together, we explore why these models are essential to his work, what it takes to build a model that understands biology, and how Noetik is creating and sourcing their datasets. Ron also shares insights on scaling and training these models, the challenges his team has faced, and how effective analysis helps determine a model’s quality. To learn more about Noetik’s innovative achievements, Ron’s advice for leaders in AI-powered startups, and much more, be sure to tune in!
|
|
|
|
|
|
 |
Research: Geographical Generalizability
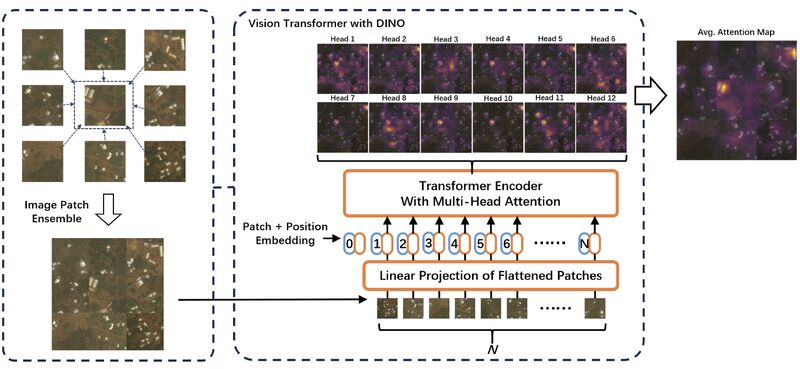
Rethink Geographical Generalizability with Unsupervised Self-Attention Model Ensemble: A Case Study of OpenStreetMap Missing Building Detection in Africa
Machine learning models trained on geospatial data from one region can easily fail when applied to another. And getting sufficient annotated training data from every region that you want to apply your model to frequently isn't possible.
Hao Li et al. proposed an unsupervised method for adapting a model to a new region.
They first trained a model on a region where they had plenty of labeled training data. Much smaller datasets are available for other regions, so they used few-shot transfer learning to adapt their model to each new region.
To apply this set of models to a new region, they used an ensembling approach and experimented with different weighting methods.
When they applied their approach to detecting OpenStreetMap missing buildings across different countries in sub-Saharan Africa, the best weighting turned out to be using self-attention.
This approach could provide value to other geospatial applications, as well as medical applications with technical and biological variations.
|
|
|
|
|
|
 |
Research: Foundation Models
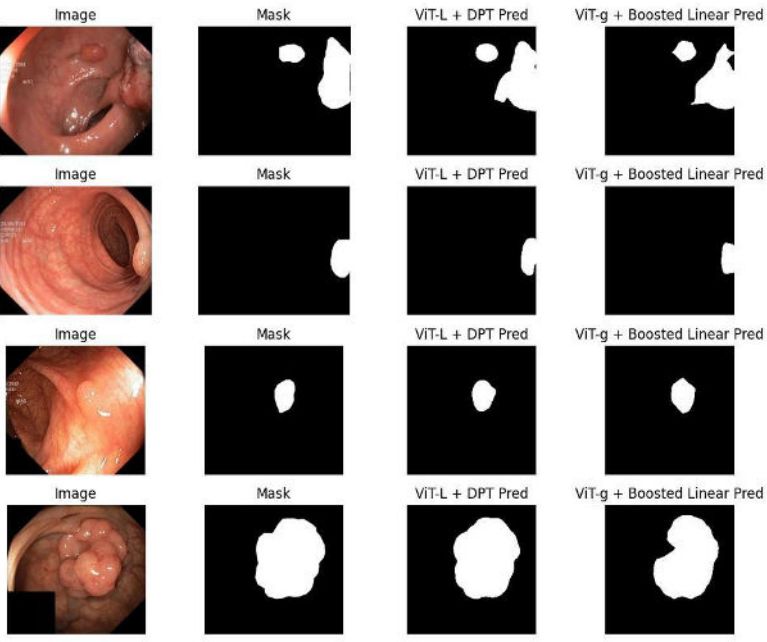
EndoDINO: A Foundation Model for GI Endoscopy
Foundation models have made it significantly easier to tackle new downstream applications. However, they are most successful when trained on a particular domain of data.
This example from Patrick Dermyer et al. at Virgo Surgical Video Solutions is focused on endoscopy videos.
Using Meta's DINOv2 framework, they trained a foundation model called EndoDINO on 130k endoscopy videos.
The entire dataset of videos contained 3.5 billion images, so they used clustering to reduce the training set down to 10 million images, while focusing on image diversity.
Experiments on anatomical landmark classification, polyp segmentation, and 3-class scoring showed that, even without finetuning, EndoDINO beat an ImageNet-pretrained model. Even when significantly fewer labeled images were used in a supervised model, EndoDINO was still the winner.
Blog |
|
|
|
|
|
 |
Research: Domain Generalization
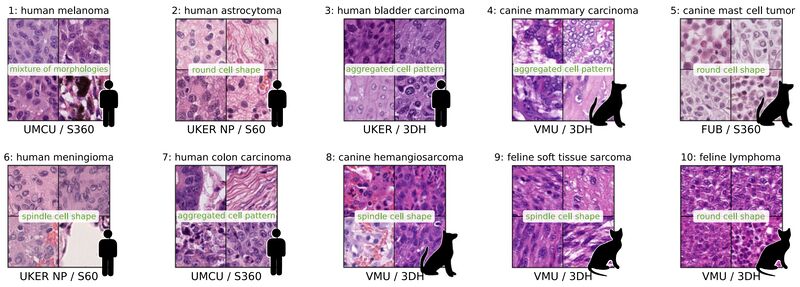
Domain generalization across tumor types, laboratories, and species — Insights from the 2022 edition of the Mitosis Domain Generalization Challenge
Domain shifts caused by different technical and biological variations are a constant challenge in building deep learning models.
Marc Aubreville et al. wrote about what they learned from organizing the challenge on MItosis Domain Generalization (MIDOG 2022).
The challenge covered multiple types of covariate shifts: different scanners (causing color, sharpness, and depth of field changes), different tumor types, and various species (human, canine, feline).
Many teams used a two-stage approach with an initial object detector locating possible mitoses, followed by a classifier to distinguish real mitoses from hard negatives. This two-stage method is common when detecting challenging objects.
However, there was also a lot of variety in the solutions: "the top three approaches to track 1 of the challenge used distinctively different strategies to address the pattern recognition problem (semantic segmentation followed by connected components analysis, object detection, and classification on a sliding window), highlighting that the how (i.e., augmentation, sampling scheme, post-processing) of training was likely more important than the what (i.e., the neural network architecture). One commonality between the three top performing approaches to track 1 was that they all used some form of ensembling technique."
Some are some great ideas in this paper for anyone tackling a domain generalization challenge!
|
|
|
|
|
|
 |
Podcast: Impact AI
Foundation Model Series: Accelerating Pathology Model Development Using Embeddings with Julianna Ianni from Proscia
How can foundation models accelerate breakthroughs in precision medicine? In today’s episode of Impact AI, we explore this question with returning guest, Julianna Ianni, Vice President of AI Research and Development at Proscia, a company revolutionizing pathology through cutting-edge technology. Join us as we explore how their platform, Concentriq, and its new Embeddings feature are transforming AI model development, making pathology-driven insights faster and more accessible than ever before. You’ll also learn how Proscia is shaping the future of precision medicine and discover practical insights for leveraging AI to advance healthcare. Whether you're curious about pathology, AI, or innovations in precision medicine, this episode offers invaluable takeaways you won’t want to miss!
|
|
|
|
|
|
 |
Research: Foundation Model Adaptation
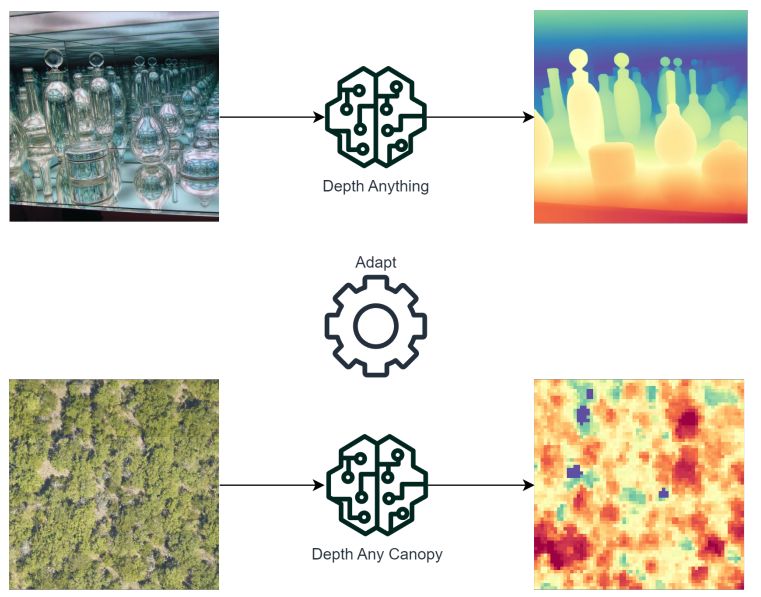
Depth Any Canopy: Leveraging Depth Foundation Models for Canopy Height Estimation
Foundation models have enabled much quicker training of models for downstream tasks and with less labeled data than before.
This example in estimating canopy heights with remote sensing is no exception.
Daniele Rege Cambrin et al. adapted the Depth Anything v2 model that was trained on natural imagery for monocular depth estimation. With a limited training set of aerial images paired with canopy height maps generated by LIDAR, they finetuned Depth Anything to create Depth Any Canopy.
Depth Any Canopy significantly improved tree canopy height estimation over the original Depth Anything. In some cases it was outperformed by a significantly larger model by another research group, but this model required much greater resources to train.
This work demonstrates how foundation models can be easily adapted to new tasks with fewer resources than alternative approaches.
|
|
|
|
|
|
|
