Beyond Accuracy: The Hidden Drivers of AI That Lasts
Accuracy is the easiest metric to measure — and the least predictive of real-world success.
Every AI team learns this eventually. The model looks brilliant in validation, the metrics sparkle, the dashboards glow green. Yet months later, it’s quietly shelved — not because it failed technically, but because it failed to last.
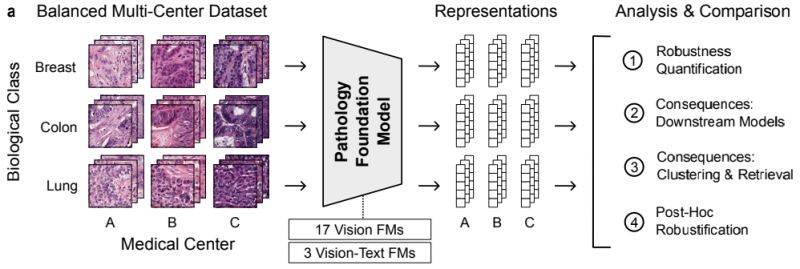
In medical imaging, one system correctly flagged anomalies in every internal test. But when deployed at a second hospital, its performance collapsed. The culprit wasn’t the model; it was the scanner. Slight differences in calibration produced colors that the algorithm had never seen. Accuracy was perfect on paper — and meaningless in practice.
That’s the danger of chasing metrics that measure prediction but not persistence.
The AI that lasts — the kind that earns trust and scales across environments — isn’t the one that wins the benchmark. It’s the one that survives the messy realities of deployment.
The Hidden Drivers of Lasting AI
When I audit underperforming computer vision systems, three overlooked forces keep reappearing. They’re not flashy, but they determine whether an AI system delivers real-world value or becomes another stalled pilot.
1. Variability Testing
Most validation schemes are designed for speed and accuracy, not stress. Teams randomly split a single dataset into train and test sets, ensuring statistical rigor but not operational realism.
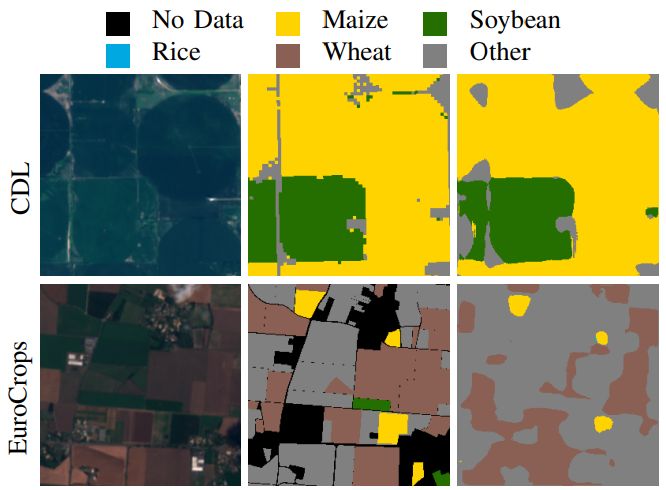
The real challenge is to test variability: new sites, new devices, new time periods, new conditions. That’s where models that look perfect on paper start to falter — and where truly robust ones prove their worth.
Cross-site validation in pathology, cross-sensor validation in agriculture, cross-season validation in earth observation — these are the experiments that reveal if your model generalizes or just memorizes. They’re slower, but they save months of rework later.
2. Domain Alignment
Many AI teams treat “data” and “domain” as separate concerns: the ML engineers handle the data and modeling, and the experts review results at the end. But that’s how shortcuts sneak in.
Without continuous domain input, models learn correlations that don’t hold up in practice — staining differences mistaken for cancer, lighting conditions mistaken for stress, noise mistaken for signal.
Keeping domain experts in the loop — not just during annotation, but in model critique and error review — grounds your AI in the real phenomena it’s meant to understand. That’s how data turns from pixels into meaning.
3. Maintainability Over Time
AI doesn’t age gracefully. Environments evolve, data drifts, and instruments are recalibrated. A model that works flawlessly today might degrade silently next quarter.
That’s why the teams that succeed treat models as living systems:
They monitor performance in production.
They version data and retraining sets.
They establish thresholds for when to retrain — not reactively, but proactively.
These processes aren’t glamorous, but they create resilience. They make AI predictable enough to trust and stable enough to scale.
From Accuracy to Accountability
Lasting AI isn’t just robust — it’s accountable. It can explain how it works, adapt when the world changes, and justify its place in a workflow.
That’s why I launched the State of Impactful AI Survey: to uncover how real organizations define and sustain success beyond the benchmark.
The survey explores questions like:
Which principles — robustness, transparency, sustainability — matter most when AI leaves the lab?
Where do teams get stuck: variability, domain alignment, or maintenance?
How are leaders balancing speed, cost, and long-term reliability?
It’s less about counting failures — and more about learning how teams build systems that last.
Why This Matters
Accuracy might help you publish a paper or impress a demo day crowd. But impact requires something deeper: durability, trust, and alignment with the real world.
When AI fails quietly — when it’s never adopted, never trusted, never scaled — the world loses out on progress that could have mattered.
If your organization has built AI that technically worked but didn’t deliver outcomes, your experience can help shape the roadmap for what comes next.
👉 Contribute to the State of Impactful AI Survey
Because accuracy might win the leaderboard — but robustness, trust, and actionability win the world.
- Heather
|