Some foundation models have become household names over the past year: GPT, DALL-E, Segment Anything. But they may not be much help for your unique images.
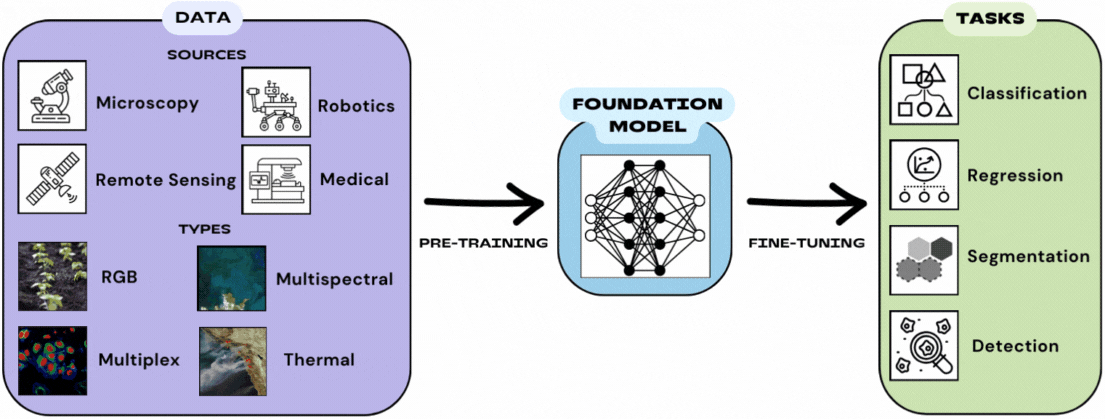
Foundation models are built on the concepts of generality and adaptability. They are trained on a broad dataset and can be finetuned for a wide variety of applications and downstream tasks – a process called transfer learning. Downstream tasks can be for any sort of thing that you might train a deep learning model for.
Foundation models form the foundation from which you can build your machine learning capabilities and don’t require labels to train.
This approach has become the state-of-the-art for natural language processing over the last few years. Best practices for computer vision are still evolving but look to be following the trend set by large language models. The difference is that transfer learning does not work nearly as well when the data is different. In comparison, a specialized model for legal texts can be finetuned from one trained on text gathered from the internet. Image structure varies much more across domains. Small-scale textures may be similar, but the next level up – the “words” – are different.
For computer vision, there are a variety of foundation models built on “natural imagery” – photos of people, places, and things.
But what if your images are different?
That’s where unlocking the patterns in your proprietary image dataset becomes key.
From Broad to Domain-Specific Foundation Models
While the foundation model paradigm has largely been applied to very diverse text or image data, it can also be applied more narrowly. Instead of across all “natural” imagery or even all types of medical images, you might apply it to a specific modality. Let’s say multiplex immunofluorescence or imagery from a particular satellite.
What qualifies as a “foundation model” may vary by the use cases envisioned. You could train one foundation model from a globally distributed set of satellite images and be able to apply it to any task that uses imagery with the same set of spectral bands. Or you might focus on satellite images of agriculture and carefully collate your dataset to capture a diverse set of crops and geographic regions. This latter foundation model will be more suitable for classifying crop types, identifying field boundaries, and quantifying carbon.
Pretraining with Self-Supervised Learning
To take advantage of large amounts of data, foundation models are typically trained without labels. They are usually built using an approach called self-supervised learning, which uses a pretext task to learn a representation that can benefit downstream tasks.
The pretext task could involve predicting cluster labels, making nearby patch encodings similar and far away ones different, reconstructing some missing parts of an image, or some other domain-specific task like predicting the magnification level. In order to complete the task, the model must learn how to represent the images and the patterns within them. Once a model has been trained with one of these pretext tasks, it can be transferred with or without finetuning to another task on similar imagery.
This paradigm shift from supervised to self-supervised pretraining is fairly recent. For the past decade, most computer vision models were finetuned from models trained in a supervised manner on ImageNet – the ubiquitous dataset of computer vision that includes 1000 classes and more than a million images. But it is time-consuming and expensive to label a whole dataset. With self-supervised learning, you can learn the patterns from a larger set of images without needing to label all of them. You only label what you need for downstream tasks.
Benefits of Domain-Specific Foundation Models
We’ve covered the what and the how, so let’s get deeper into the why. Why would you want to build a domain-specific foundation model?
#1 Adaptable to Many Different Downstream Tasks
Foundation models are trained to learn a representation for the input data that can be useful for not only their pretext task but also for many other downstream tasks. Regardless of whether it’s classification, regression, semantic segmentation, object detection, or something else, they can be used as a simple means of extracting features or finetuned to perform even better for a specific task.
#2 Increased Accuracy on Downstream Tasks
In experiments on a diverse set of application areas, foundation models have been shown to result in a higher accuracy than models trained from scratch or transferred from ImageNet. Fully supervised models may still be superior when millions of labeled examples are available, but the annotation efforts are too costly for most applications.
#3 Less Reliance on Labeled Data
Achieving a comparable level of accuracy with a fully supervised model often requires five to ten times as much labeled data. Certainly the more labeled data for the downstream task the better, but, with a foundation model trained on your unlabeled data, you can reduce your annotation efforts. You can even accommodate datasets with a long tailed distribution or with weak labels.
#4 Improved Generalizability to Distribution Shifts
Foundation models that are trained on a diverse set of imagery – including a variety of different distributions – are more robust to distribution shifts. This means that a model trained on a limited training set still can perform better when applied to data from a different scanner, lab, geographic region, vegetation type, lighting, weather conditions, etc. The nature of the shift depends on the imaging domain, but foundation models can be more generalizable.
#5 Potential for Multiplex/Multispectral or Time Series Inputs
When training a model from scratch for a specific domain, the nature of that type of imagery can be accommodated. If the imagery is multiplex or multispectral – meaning that it has more than the typical three channel RGB inputs – the foundation model can learn the relationships between the different channels or bands. The model could even input a time series of images – satellite imagery, for example. Downstream tasks can benefit from this more comprehensive image representation.
#6 Reduced Computational Needs for Future Projects
The most computationally intensive component of training a deep learning model is in optimizing the model parameters from an initial set of random weights. It can take hundreds of epochs to converge to a usable model. But with a foundation model, you only do this heavy lifting once. Finetuning for downstream tasks is much faster and requires fewer resources.
#7 Eliminate Dependency on Publicly Available Models
Most computer vision models are trained by finetuning a pretrained model from ImageNet or some other publicly available dataset that may be copyrighted. For imaging domains with vast amounts of unlabeled data available – H&E histology or satellite imagery, for example – research groups with extensive computing resources have started releasing their foundation models to the public. Using such a model may give you a headstart or it may cause additional headaches and impede generalizability. If you train your own model, you are in control and can add additional data to model training in the future.
Roadmap to a Custom Domain-Specific Foundation Models
If there is a publicly available foundation model trained on imagery similar to yours, go ahead and give it a try. It doesn’t hurt to evaluate it before considering investing in your own domain-specific foundation model.
But if you can already envision the benefits of a custom model for your team, then the next step is a more detailed analysis of the ROI. Some of the benefits mentioned above are more relevant for some applications than others. And the costs associated with training a foundation model also need to be considered.
Training a foundation model is not an easy feat. If you have vast quantities of unlabeled data, then it’s not just about the mechanics. The compute resources, scalability, and efficiency must also be considered.
If your dataset is smaller – let’s say fewer than 100k images (or image patches in the case of larger images) – the compute resources are less extensive, but the methodology to successfully train a foundation model is much more important.
What types of image augmentation are appropriate? How should your dataset be balanced to capture the full diversity? What pretext task can take full advantage of the limited quantity of data and produce the best representation for downstream tasks?
The answers are more critical for smaller datasets and are nuanced by the unique characteristics of the imaging modality and subject matter.
Next Steps
As outlined above, domain-specific foundation models bring many benefits to computer vision applications. However, they can be complex to train, and the challenges vary with the characteristics of the dataset.
Does your organization have an image dataset from a unique modality? Start your journey to a foundation model with a Foundation Model Assessment. Get a clear perspective on the ROI for your proprietary image data before wasting months of experimentation on the wrong path.